By Aashish Joshi | Founder & CEO

Random Forest is a supervised machine learning model that is widely used in solving both regression and classification problems. This model relies on an ensemble technique that combines the output of multiple, often hundreds of decision tree models that yields a superior modeling technique and hence a far more robust outcome.
It is thus important to first comprehend how a decision tree model works so that this fundamental understanding can be extrapolated to better internalize the mechanism of the random forest model. For ease of understanding, the Decision Tree model for a classification problem will be explained using a dataset with 7 observations, containing 3 independent variables and 1 dependent variable. Data: The data points mentioned below are directly taken from the IBM HR Analytics dataset.
| OverTime | Gender | Age | Attrition |
| Yes | Male | 32 | No |
| Yes | Female | 29 | No |
| No | Male | 36 | Yes |
| No | Male | 51 | Yes |
| Yes | Male | 37 | Yes |
| Yes | Female | 47 | No |
| No | Female | 53 | No |
Note that these attributes have already been explained in the research environment hence we will now proceed with implementing a Decision Tree model
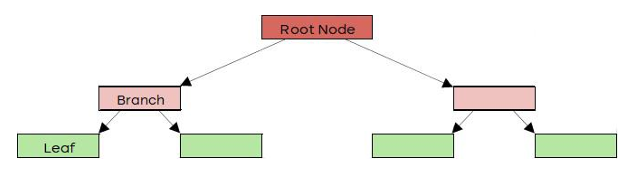
1. Decision Tree Structure/Terminology:
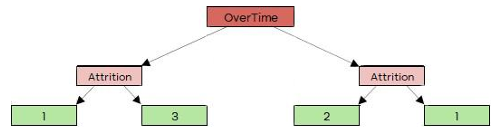
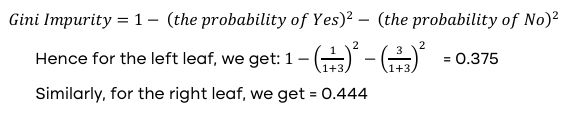

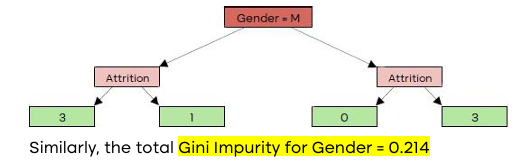
Hence total Gini impurity for OverTime = 0.405
| OverTime | Gender | Age | Attrition |
| Yes | Female | 29 | No |
| Yes | Male | 32 | No |
| No | Male | 36 | Yes |
| Yes | Male | 37 | Yes |
| Yes | Female | 47 | No |
| No | Male | 51 | Yes |
| No | Female | 53 | No |
Age < 30.5
Age < 34
Age < 36.5
Age < 42
Age < 49
Age < 52
| Age Threshold | Gini Impurity |
| 30.5 | 0.429 |
| 34 | 0.343 |
| 36.5 | 0.476 |
| 42 | 0.476 |
| 49 | 0.486 |
| 52 | 0.429 |
3. Determining Branch/Internal Node variables:
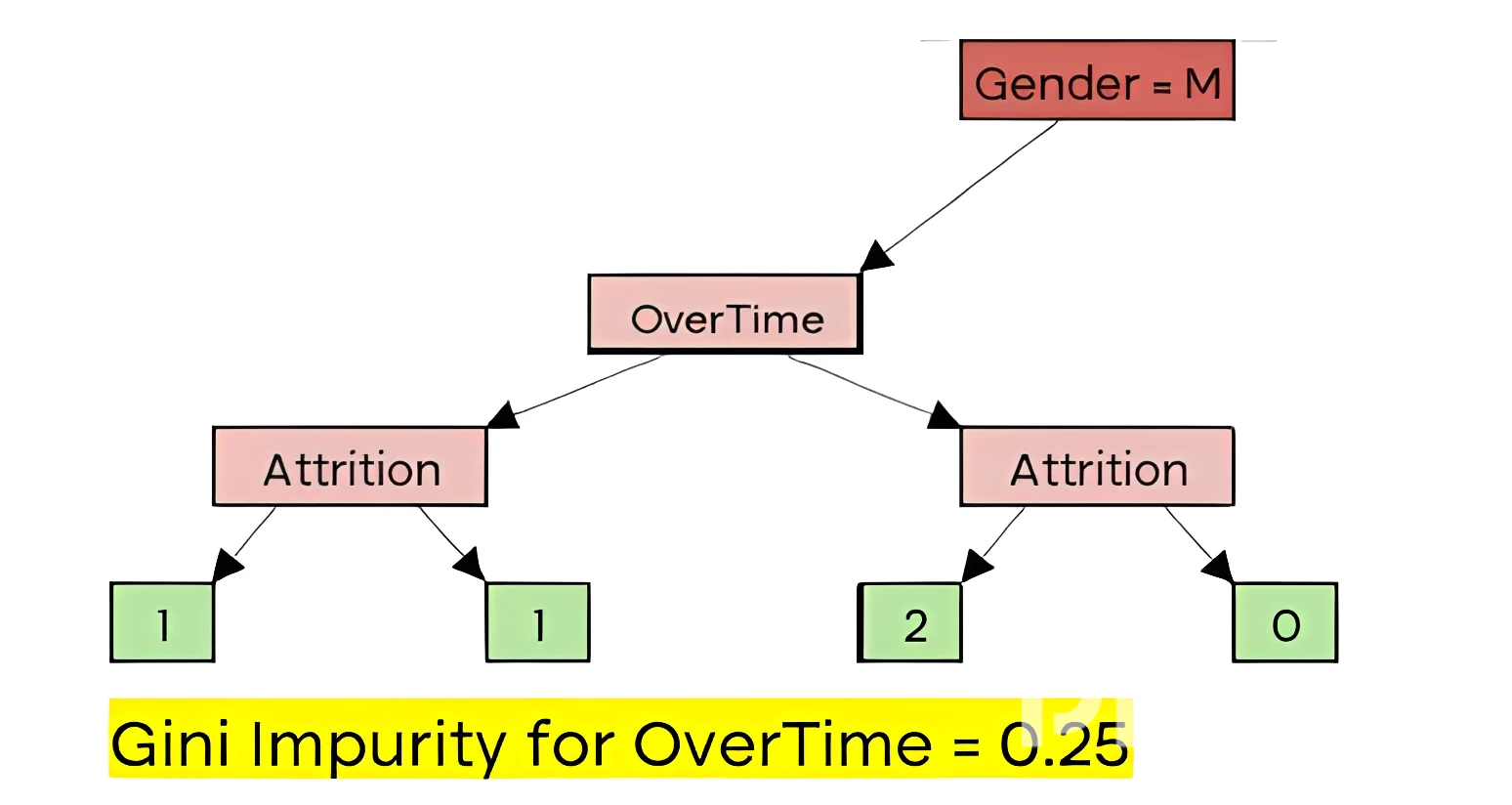
| OverTime | Gender | Age | Attrition |
| Yes | Male | 32 | No |
| No | Male | 36 | Yes |
| Yes | Male | 37 | Yes |
| No | Male | 51 | Yes |
Hence the possible splits are:
Age < 34
Age < 36.5
Age < 44
| Age Threshold | Gini Impurity |
| 34 | 0 |
| 36.5 | 0.25 |
| 44 | 0.33 |
Comparing the Gini Impurity values for OverTime and Age, we can see that Age has the lower impurity value and thus will be selected as the branch variable.
4. Calculating Output Values for all leaves:
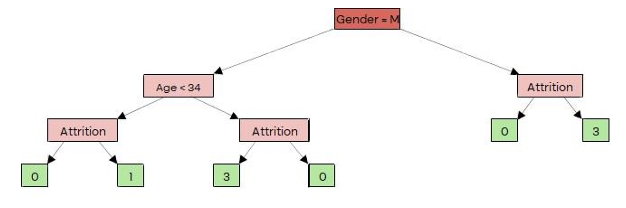
Hence the final decision tree structure is as shown below:
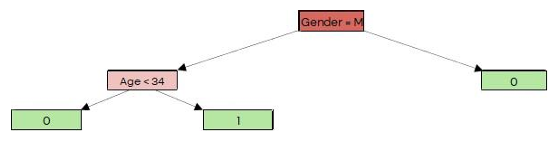
Here 0 = employee will stay with the organization
1 = employee will exit the organization
5. Building the Random Forest Model: